从报名比赛开始到现在将近四个月了,终于告一段落,最终拿到了季军也很开心。这三个月中我学到了很多有用的工程知识,顺便把 C++ 又摸熟了。初赛代码实在写太丑就不放出来了,复赛的代码托管在 github 上:
https://github.com/arkbriar/awrace2018_messagestore
下面是本次大赛初赛和复赛部分的思考过程和最终方案。
初赛部分
赛题背景分析及理解
实现一个高性能的 Service Mesh Agent 组件,并包含如下一些功能:1. 服务注册与发现, 2. 协议转换, 3. 负载均衡
本题要求我们能够尽可能的高性能,我们首先对场景和大致思路进行了一个重述:
- Consumer 将接受超过 500 个连接:想到使用 IO multiplex
- Http = TCP 连接:禁用 Nagle 算法
- Dubbo provider 只有 200 个处理线程,超过 200 个并发请求会快速失败: 负载均衡尽量避免 provider 过载
- 线上网络性能 (pps) 较差:批量发送 request/response,使用 UDP 进行 Agent 间通信
- Consumer 性能较差:将协议转换等放到 provider agent 上去做
核心思路
为了减少系统开销,我们在 agent 之间都只保持一个 udp 信道,在 PA (Provider Agent) 和 Provider 之间也只保持一个 tcp 信道。
整体的架构图如下所示:
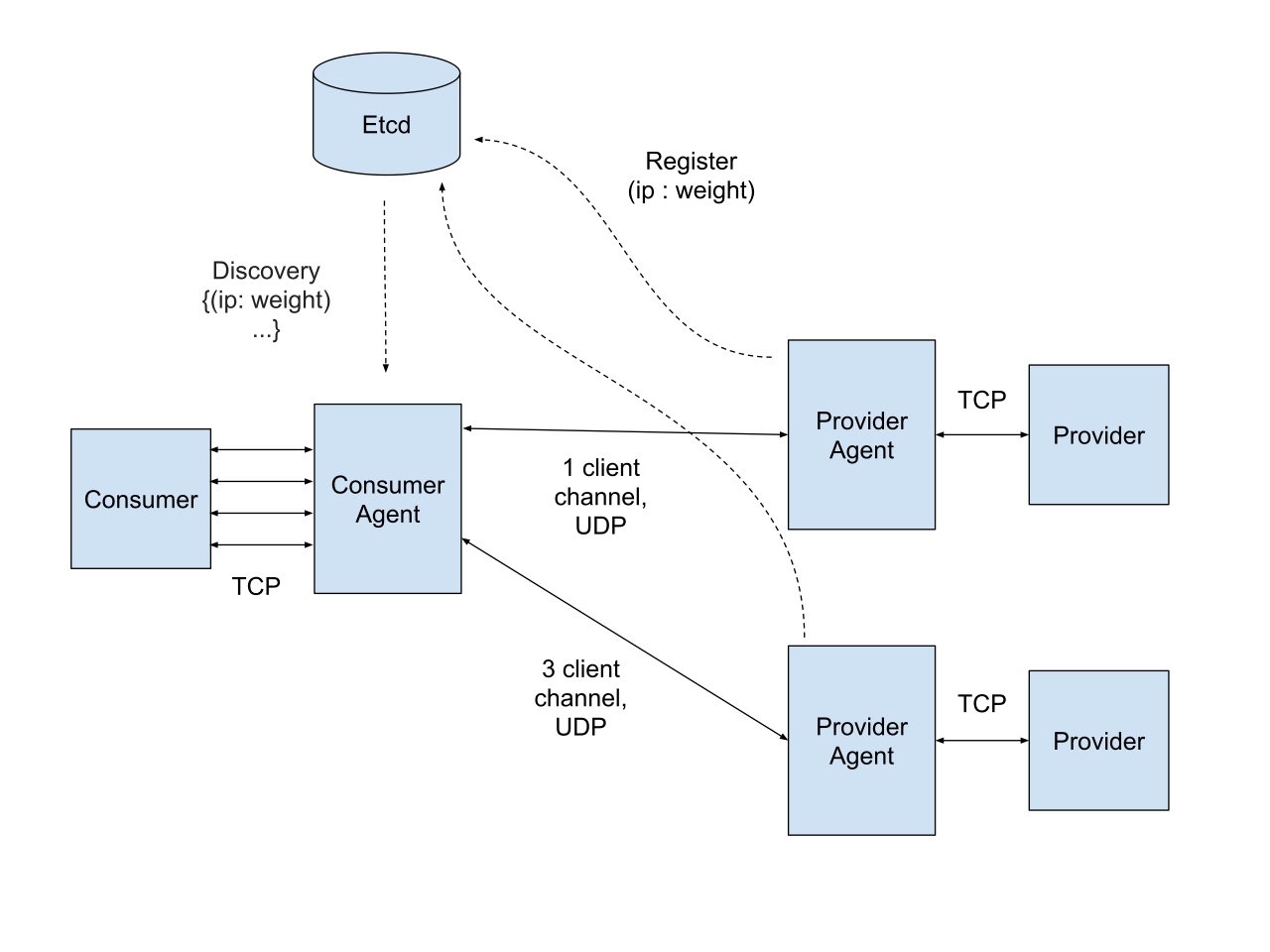
其中,CA (Consumer Agent) 端使用一个 epoll 的 eventloop,loop 的大致流程如下图:
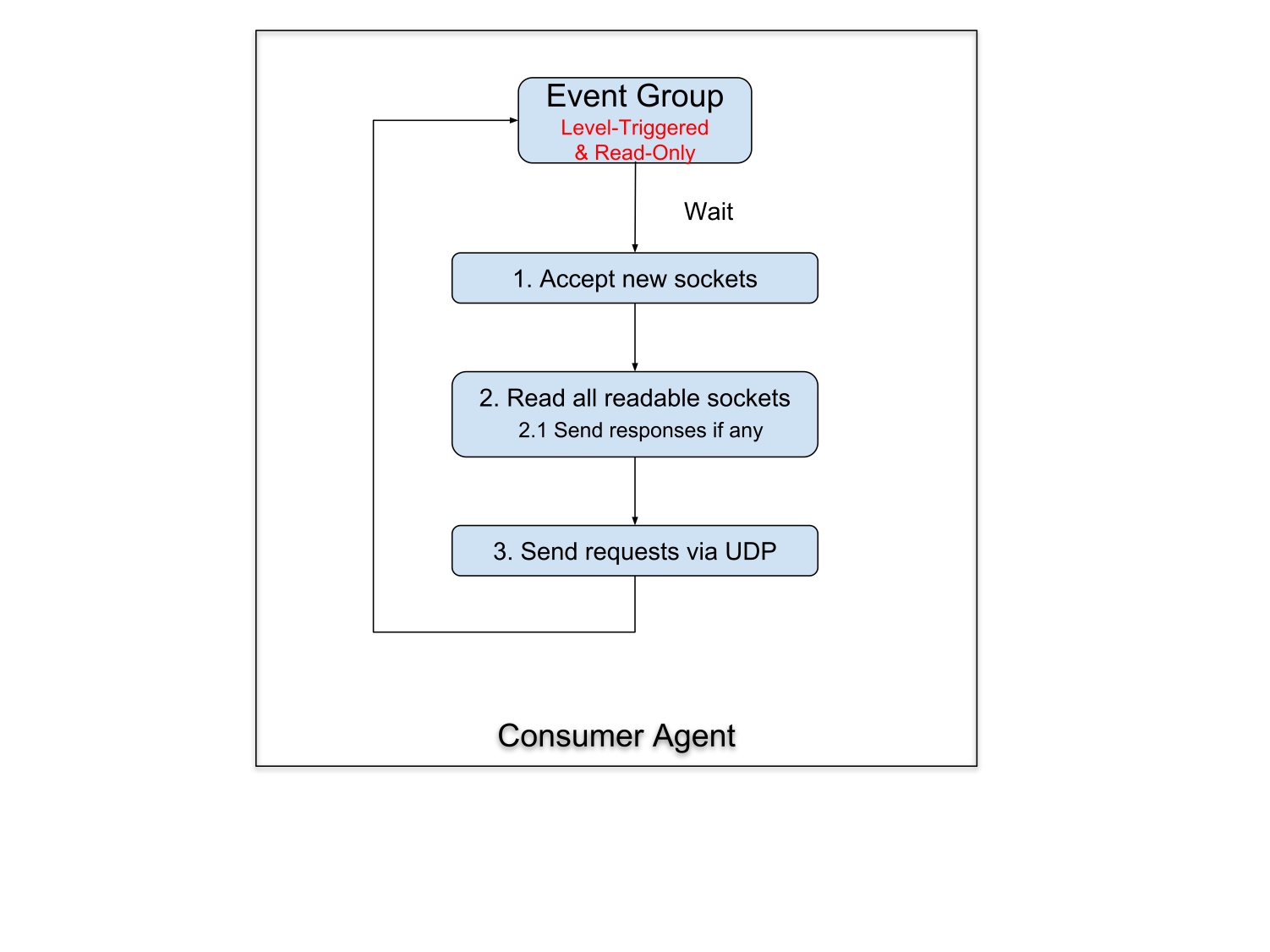 1. 首先接起所有的新的连接,在接到连接的时候,根据 provider 的权重直接分配一个 provider 处理后续该连接的所有请求
1. 首先接起所有的新的连接,在接到连接的时候,根据 provider 的权重直接分配一个 provider 处理后续该连接的所有请求
2. 读所有的能读的 socket
- 如果读到完整的请求,那么将它放入到请求队列
- 如果读到完整的回复,直接通过阻塞写的方式写回
3. 所有事件处理完成以后,批量发送所有的请求队列 (此处使用 writev)
在请求发送和获取回复的过程中,我们始终有一个 id 附在请求中,这个 id 是 consumer 端唯一的,这保证了我们只在 consumer 端有一个 map 来确定回复的归宿,在这里我们的 id 是 handler 的编号。
关键代码
批量发送请求代码大致如下:
epoll_event events[LOWER_LOAD_EVENT_SIZE];while (_event_group.wait_and_handle(events, LOWER_LOAD_EVENT_SIZE, -1)) { // check pending write queue, and block write all for (auto& entry : _pending_data) { // write all requests to provider agent // ... }}复赛部分
赛题背景分析及理解
实现 Queue Store 的接口 put/get,要求支持单机百万队列和百 G 数据。
在对题目稍微了解过后,我们得到了以下的几个信息:
- 消息条数大约为 2g,消息大小大约为 64 byte,但是可能会有长为 1024 byte 的消息
- 线上的机器是 4c8g 带 ssd,iops 1w 左右,顺序 4k 读写性能大约为 200m/s 左右
- 对同一个队列,put 是序列化的
- 对同一个队列,get 可能是并发的
- 不存在删除队列和消息,也不存在 put 与 get 同时进行
而评测程序的空跑 put TPS 大约在 600w 左右,性能也不是很高;而在不压缩的情况下,写打满写 100g 数据最少耗时 500s。因此本题要求选手能够尽可能的保证 put 阶段的无阻塞,以及能够设计出一个良好的数据结构,保证 get 阶段能够利用缓存和局部性。
核心思路
为了实现高性能的接口,我们必须要解决以下三个问题:
- 存储设计问题,要求能够支持顺序写与随机读
- IO/SSD 优化问题,能尽可能的使 IO 做到极限
- 内存规划问题,由于评测环境内存比较有限,需要紧凑的规划和使用
存储设计:页式存储
首先我们研究了一个比较类似的产品,Kafka:
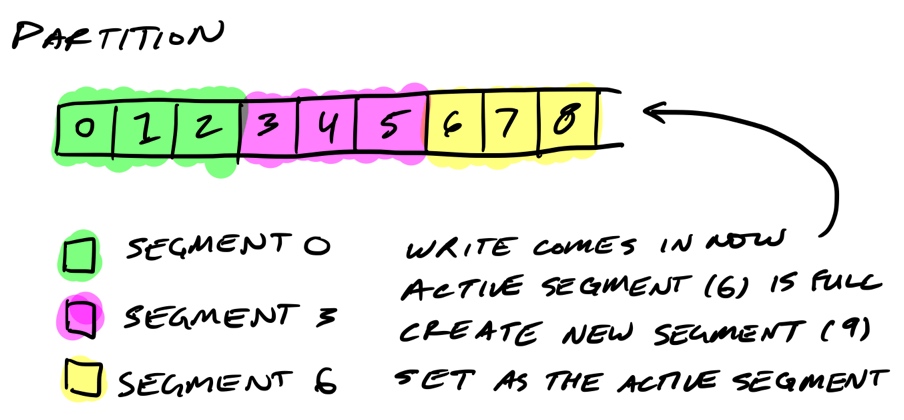
Kafka 的大致存储模型如上图所示,这里并不展开叙述,有兴趣的同学可以到这个网站继续学习 https://thehoard.blog/how-kafkas-storage-internals-work-3a29b02e026
但是对于我们来说,照搬它有很多问题:
- 100w 个队列,至少有 200w 个文件,这对文件系统形成了巨大的负担
- Kafka 使用全量索引,而 2g 消息的全量索引根本放不进内存,至少做两级索引,这加重了读的负担
- 2g 消息的全量索引的磁盘 overhead 太大
- 队列的主要场景是顺序读,全量索引优势完全没有发挥 (随机读)
所以我们借鉴了一个常见的文件切分模式,也就是分页,并以页为最小单位进行操作和建立索引。这就是我们的存储模式:页式存储。
通过这个存储方式,
- 可以有效的减少文件的数目
- 并且由于顺序写的性质,我们并不需要考虑脏页的问题
- 同时由于页是最小单位,同属一个队列的连续消息尽可能的在一个页中,保证了顺序读能够利用缓存和局部性
- 最后,我们对页建立索引,此时的索引已经完全可以放入内存了
为了兼顾内存,页大小设置为 4k。
IO/SSD 优化:块读块写
对于现有的大多数存储设备来说,无论是 HDD 还是 SSD 也好,顺序读写永远都是最优的。
但是,SSD 有区别的一点在于,由于 SSD 的特性 “内置并发”,对齐于 Clustered Block 的读写将完全不输于顺序读写。
如果要理解内置并发这个事情,我们可能需要去了解一些 SSD 的原理,下面这个网站提供了更多的细节,在这里只叙述一部分的东西。
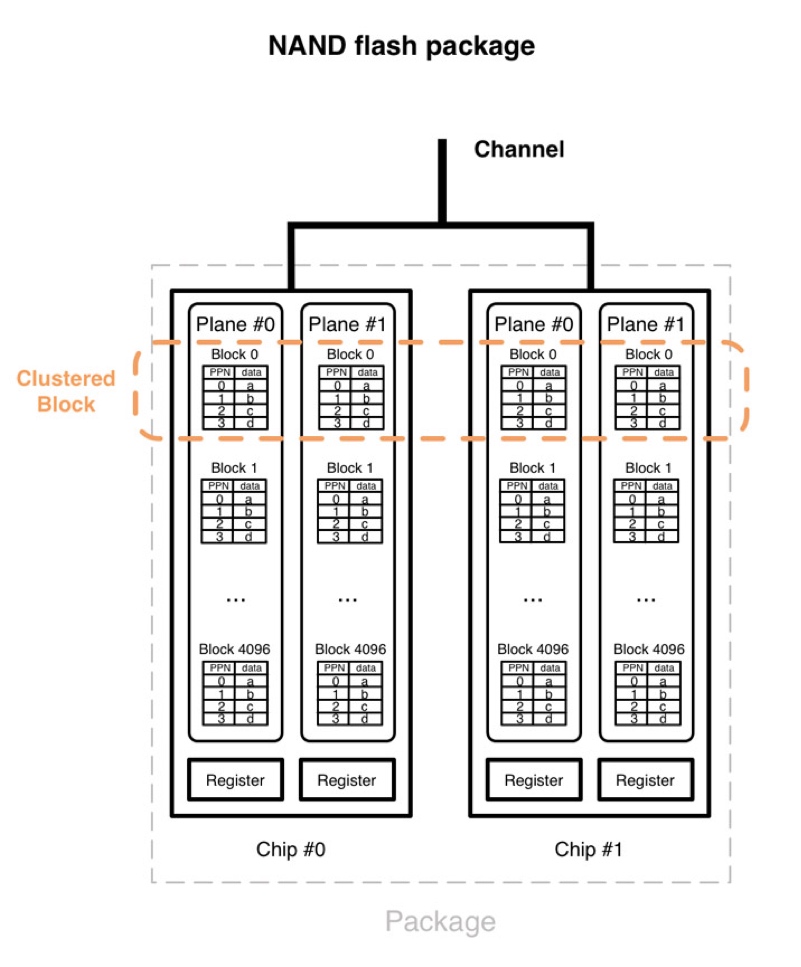
SSD 的读写都是以页 (NAND-flash page) 为单位的,即使只读/写一个 bit,也会同时读/写一个页。相邻的页组成一个块,块大小通常在 256k 到 4m 之间。 SSD 的还有些原理会导致一个写放大和 GC 的问题,这里不再展开,有兴趣的同学自行了解。
SSD 的内置并发指的是,图示上面的不同 channel/package/chip/plane 的访问都是可以并发进行的,不同的 plane 上的 block 组成的访问单位叫做聚簇块 (Clustered Block),如图示中黄色框中的部分。可以看到,读写聚簇块就能充分地并发访问,而我们接下来要讲的读写模式就是,对齐聚簇块随机读写,性能将完全不输顺序读写。这里额外提一句,通常聚簇块大小为 32/64m。
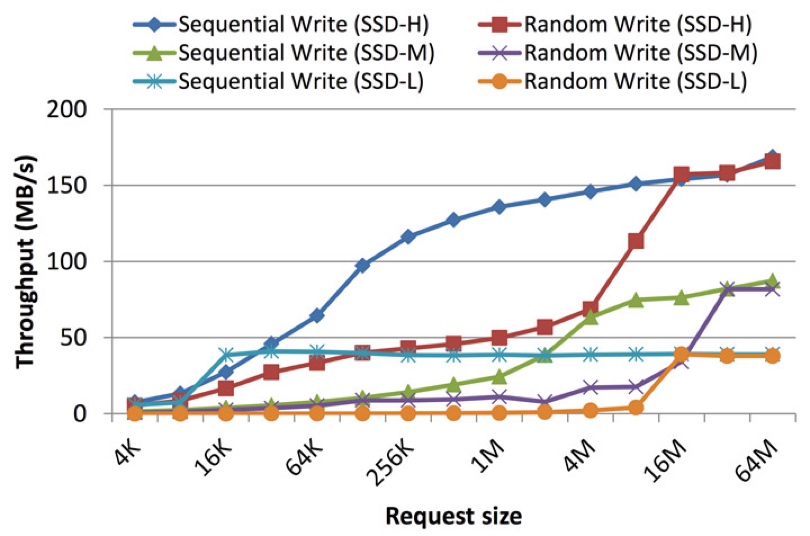
这是一张随机写与顺序写的吞吐对比,在 32M/64M 下,随机写已经能够全线等同顺序写。
而我们也做了一个小测试,测试 4g 大小的文件读写,单位都是秒:
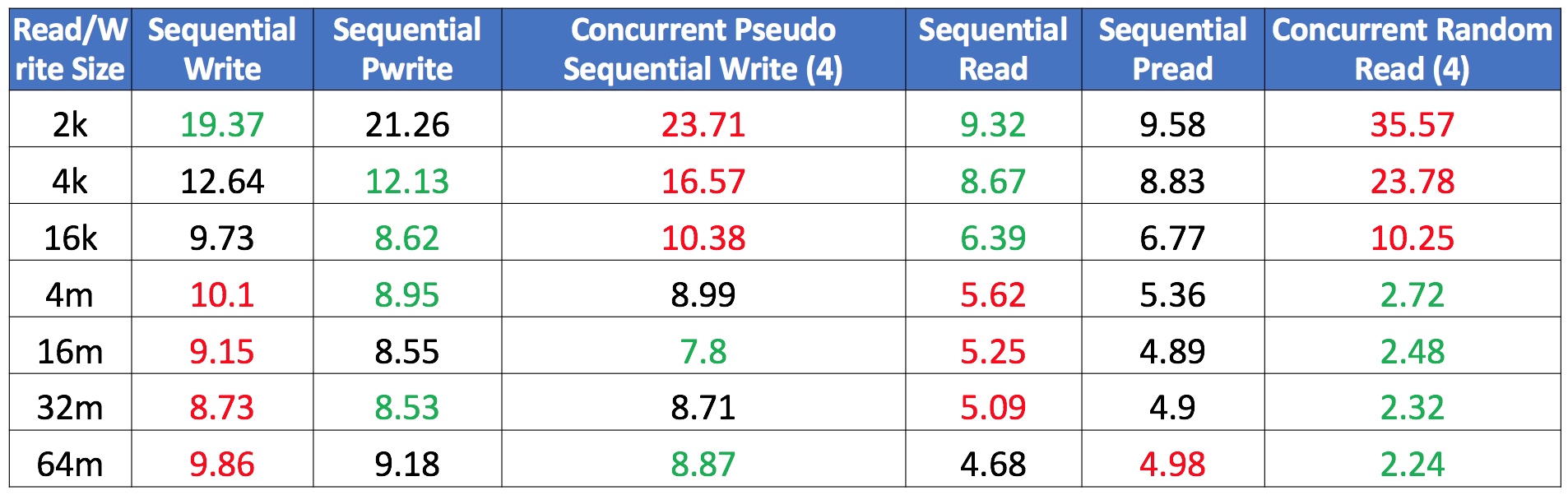
其中 concurrent pseudo sequential write 是指多个线程从同一个 atomic int 上获取下一个写 offset。实验结果证明了这个模式的有效性。
所以我们最后的读写模式为块读块写:
- 大块 (64m) 写,甚至可以不用顺序写
- 有效地提高了并发读写性能
- 顺序读时充分利用缓存和预读
内存规划:精打细算
在结合上述两个设计的基础上,我们对内存有个精确的规划:
- 每个队列有自己的 4k 页缓存,对应于当前正在写的页
- 每个 put 线程有自己的双 64m 写缓冲,缓冲永远对应某个文件的一个区间
- 总计加起来缓存共占用 4k * 1m + 64m * 2 ≈ 5.2g
整体架构
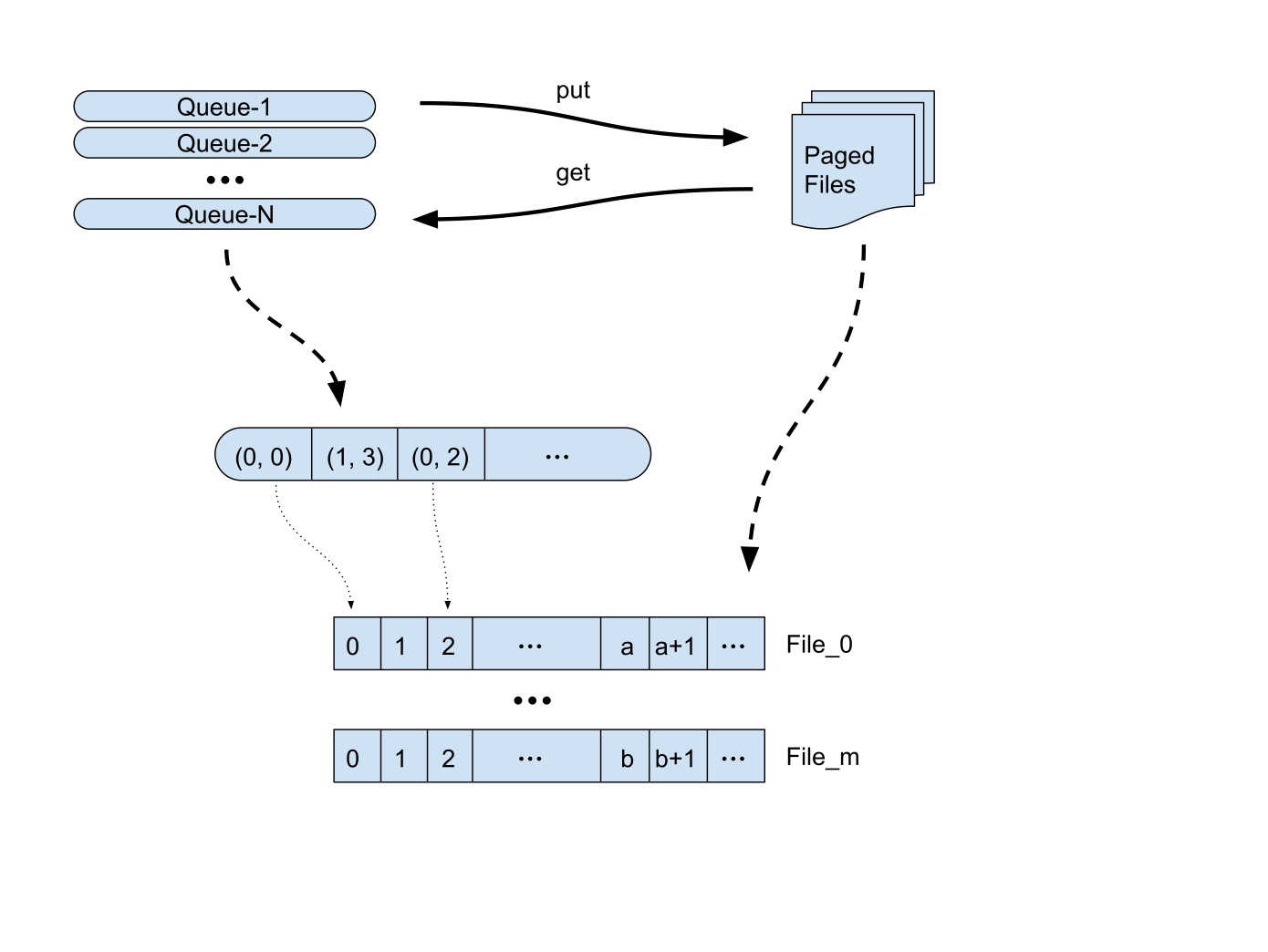
Queue 与文件的关系如下图:
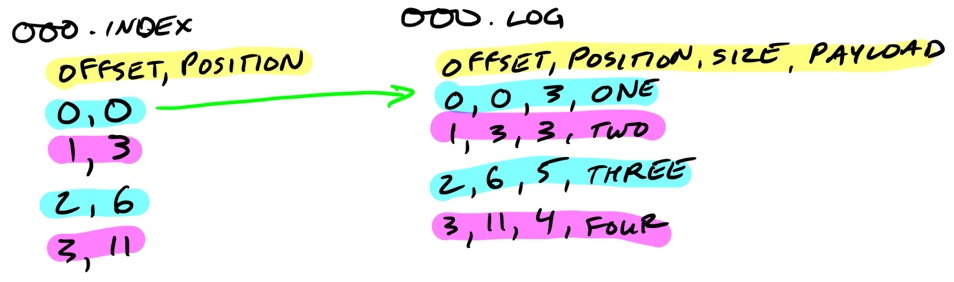
 页与消息的结构如下图:
页与消息的结构如下图:
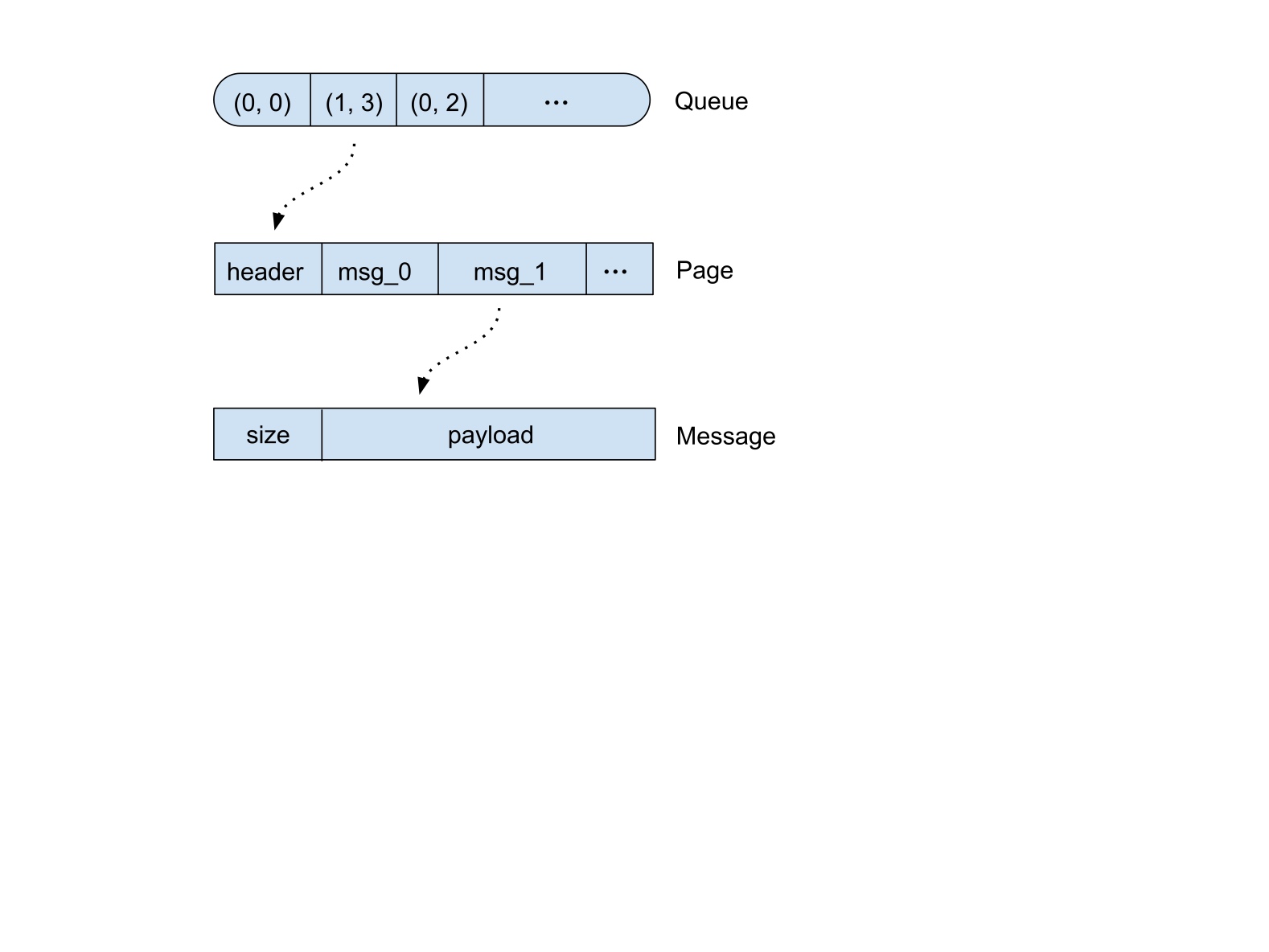 Size 的计算采用变长编码:
Size 的计算采用变长编码:
- Size < 128,使用一个 byte 存储,第一个 bit 为 0
- Size >= 128 并且 < 32768,使用两个 byte 存储,但是由于第一个 bit 也为 0,所以存储 size | 0x8000
针对每个页的索引大致如下:
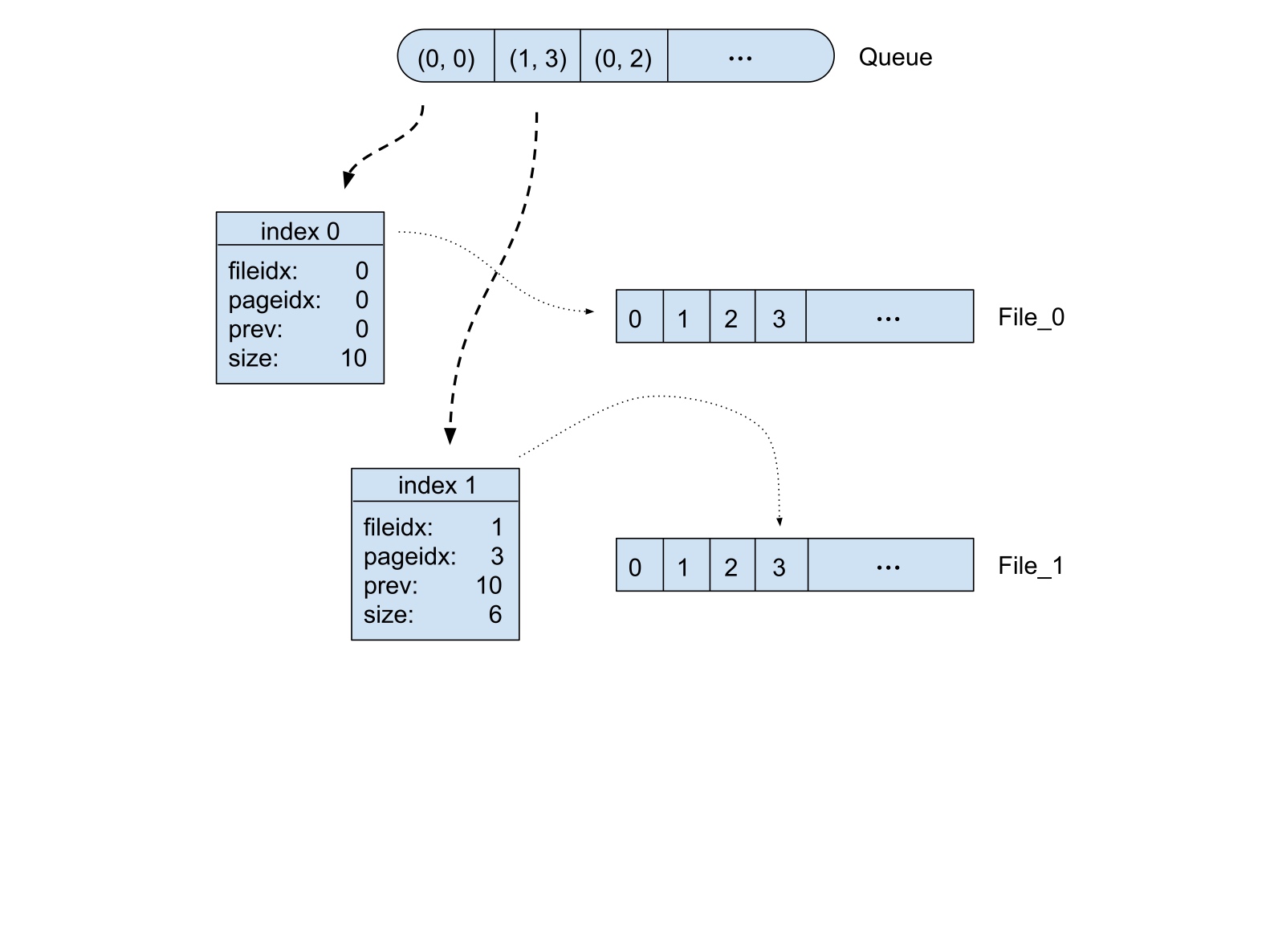
每个页存储页编号、文件编号、页内消息数和之前所有页消息数这四项,这样我们在 get 时二分查找就可以获取到对应消息所在的页。所有的索引总量大约为 12byte * 25m = 300m,完全可以放于内存。
Put/Get 流程
这两个流程相对简单,首先是 put 流程:
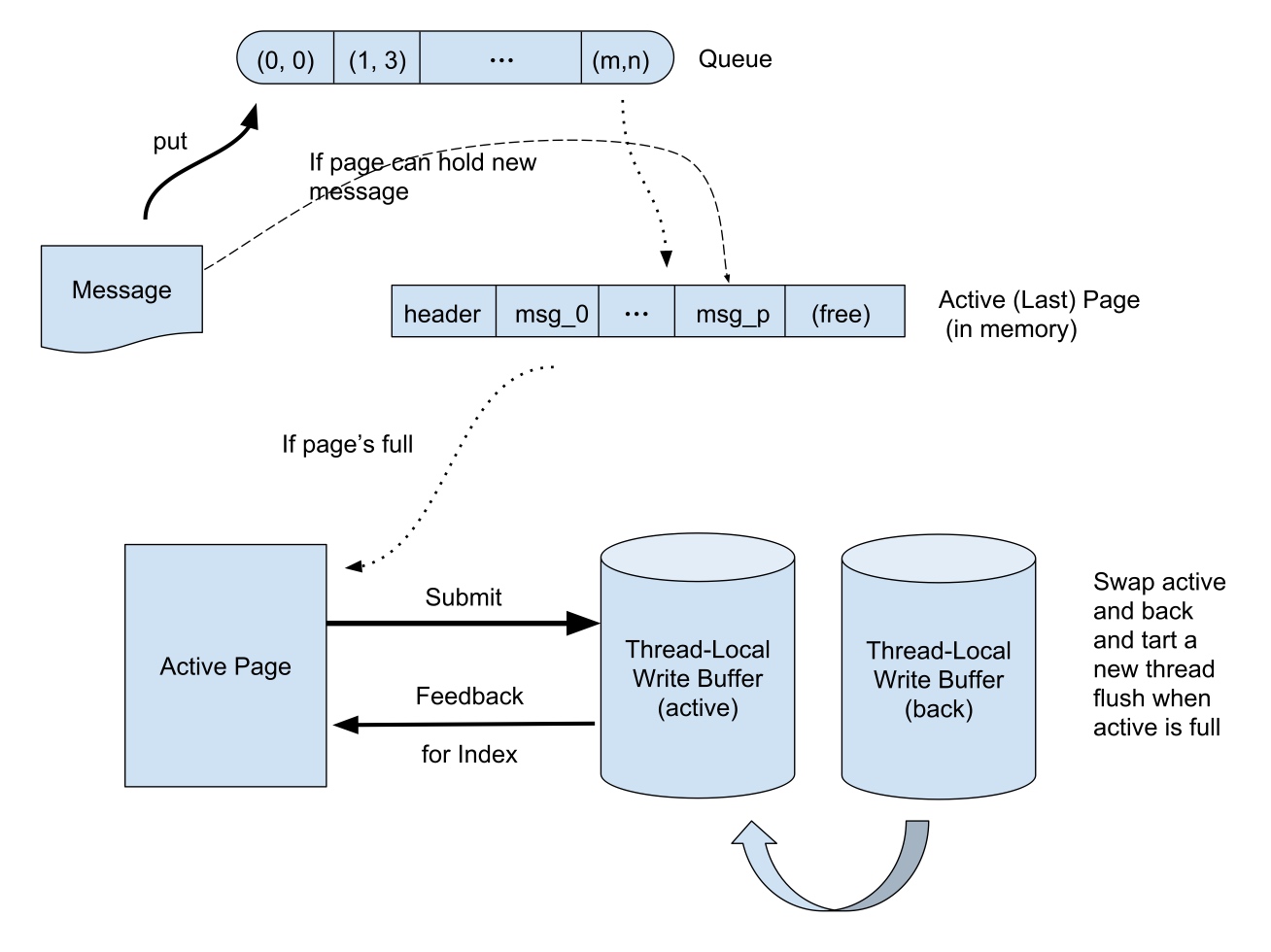
- 检查内存中的页还有没有空间
- 有,直接写入
- 没有,将当前页写出,更新索引,然后写入消息
页写出时会提交到当前 put 线程的写缓冲,并反馈修改索引。当写缓冲满的时候,与后备的缓冲交换继续写入缓冲,并起新的线程刷盘,这样尽可能不阻塞 put 线程。
在所有 get 发生前,我们会强制所有缓冲落盘,接下来的 get 流程也相对简单:
- 二分查找第一页和最后一页
- 顺序阻塞读对应的文件页
- 跳过页内无关的消息,收集所有相关消息
- 如果请求的最后一页剩余消息数小于某个阈值 (e.g. 15),使用 readahead 预读下一页
- 返回请求的消息
我们在 get 的过程中保持两个理念:
- 全力使用 OS 的页缓存
- 尽可能预读,以期望减少顺序读的时间
全力使用 OS 的页缓存主要是考虑到
- 实现 Concurrent LRU cache 比较麻烦
- 如果实现队列的一个顺序读缓冲,类似于链表结构,一旦发生多线程同时顺序读,缓冲会一直失效;即使实现 thread local 缓冲,如果出现单线程不同偏移量顺序读同一个队列 (e.g. 完整读两次),缓冲也会不断失效
所以不如直接使用页缓存。
关键代码
队列映射我们使用了 tbb 的 concurrent hash map,最终证明这是最大的 cpu 瓶颈,而我们的 put 完全卡在了 cpu 上。
template <class K, class V, class C = tbb::tbb_hash_compare<K>, class A = tbb::cache_aligned_allocator<std::pair<const K, V>>>class ConcurrentHashMapProxy : public tbb::concurrent_hash_map<K, V, C, A> {public: ConcurrentHashMapProxy(size_t n) : tbb::concurrent_hash_map<K, V, C, A>(n) {} ~ConcurrentHashMapProxy() { this->tbb::concurrent_hash_map<K, V, C, A>::~concurrent_hash_map<K, V, C, A>(); } typename tbb::concurrent_hash_map<K, V, C, A>::const_pointer fast_find(const K& key) const { return this->internal_fast_find(key); }};
MessageQueue* QueueStore::find_or_create_queue(const String& queue_name) { auto q_ptr = queues_.fast_find(queue_name); if (q_ptr) return q_ptr->second;
decltype(queues_)::const_accessor ac; queues_.find(ac, queue_name); if (ac.empty()) { uint32_t queue_id = next_queue_id_.next(); auto queue_ptr = new MessageQueue(queue_id, this); queues_.insert(ac, std::make_pair(queue_name, queue_ptr)); DLOG("Created a new queue, id: %d, name: %s", q->get_queue_id(), q->get_queue_name().c_str()); } return ac->second;}
MessageQueue* QueueStore::find_queue(const String& queue_name) const { auto q_ptr = queues_.fast_find(queue_name); return q_ptr ? q_ptr->second : nullptr;
decltype(queues_)::const_accessor ac; queues_.find(ac, queue_name); return ac.empty() ? nullptr : ac->second;}
void QueueStore::put(const String& queue_name, const MemBlock& message) { if (!message.ptr) return; auto q_ptr = find_or_create_queue(queue_name); q_ptr->put(message);}
Vector<MemBlock> QueueStore::get(const String& queue_name, long offset, long size) { if (!flushed) flush_all_before_read();
auto q_ptr = find_queue(queue_name); if (q_ptr) return q_ptr->get(offset, size); // return empty list when queue is not found return Vector<MemBlock>();}然后是我们的主要数据结构 FilePage:
// File page headerstruct __attribute__((__packed__)) FilePageHeader { uint64_t offset = NEGATIVE_OFFSET;};
#define FILE_PAGE_HEADER_SIZE sizeof(FilePageHeader)#define FILE_PAGE_AVAILABLE_SIZE (FILE_PAGE_SIZE - FILE_PAGE_HEADER_SIZE)
// File pagestruct __attribute__((__packed__)) FilePage { FilePageHeader header; char content[FILE_PAGE_AVAILABLE_SIZE];};双写缓冲有个交换上的同步,我们使用 mutex 去进行这个同步:
// buffer is full, switch to back{ // spin wait until back buf is not in scheduled status while (back_buf_status->load() == BACK_BUF_FLUSH_SCHEDULED) ; // try swap active and back buffer std::unique_lock<std::mutex> lock(*back_buf_mutex); std::swap(active_buf, back_buf); assert(back_buf_status->load() == BACK_BUF_FREE); uint32_t exp = BACK_BUF_FREE; back_buf_status->compare_exchange_strong(exp, BACK_BUF_FLUSH_SCHEDULED);}为了使得 OS 充分的跑起来,get 阶段需要释放掉所有无用的内存,然而 tcmalloc 是不会主动释放的,所以需要强制释放:
// release free memory back to osMallocExtension::instance()->ReleaseFreeMemory();由于线上的写入太过于均匀,到了刷盘的时候就是所有页缓存一起刷盘,这会造成所有 put 线程都阻塞并等待的状况,为了缓解这个情况,我们让某些队列的第一页快速写出:
// first page will hold at most (queue_id / DATA_FILE_SPLITS) % 64 + 1 messages, this make write// more average. This leads to 64 timepoints of first flush. I call it flush fast.bool flush_fast = paged_message_indices_.size() == 1 && paged_message_indices_.back().msg_size >= ((queue_id_ / DATA_FILE_SPLITS) & 0x3f) + 1;其余代码放在 https://code.aliyun.com/arkbriar/queue-race-2018-cpp 中。
最终成绩
最快写入时间大约 690s,最终缓存落盘 20s,随机校验 120s,顺序校验 140s,总计 970s+。
期间从 1.9 开始的提升全在压缩 cpu 开销,没有动过读写结构。
工程价值与健壮性
在存储设计过程中,我们充分考虑到了长消息的存在;虽然在比赛代码的实现中,我们最长支持也就是 4k 多一点的长度,但是却可以很轻易的支持跨页消息来去掉这个限制。
在 put 的设计过程中,我们充分利用了 SSD 的特性,使得即使是随机写也能达到最大的磁盘吞吐。遗憾的是,最终我们深陷 cpu 瓶颈从来没有跑出过最大吞吐。
虽然考虑到场景下没有边读边写的情况,但是通过在队列映射上加读写锁,或者在更细粒度的内存页上加锁,并在读时考虑内存中未落盘的数据,则立刻可以支持边读边写。
总结与感想
对各种知识的理解和运用是解决实际问题的关键,在与各位选手的交流与竞争中,我们学到了很多知识,相信大家通过这次比赛也能收获很多。