自上次更新博客起已经有三年时间了,这期间经历了留学、毕业、工作等很多事情,个中滋味只有自己知道。博客重开,希望文笔和思路上能比以前进步一点点。同时因为学识有限,也希望各位大佬能不吝赐教。
背景
上个月为了学习 rust 语言,参加了阿里云 ECS 团队举办的 CloudBuild 性能挑战赛,用 rust 实现一个聊天室服务器。因为 rust 不熟练初赛只提交了一次,居然也闯进复赛了,也挺有意思的。复赛题目要求服务要部署在三台机器上,同时提供完整的读写服务,且要求宕机一台不影响服务。看到题目后,我直观地想到了使用一致性协议让三台机器关于存储的数据达成一致就可。分布式系统中常用的一致性协议有 Paxos 和 Raft 等,其中 Raft 从原理上来说是一种特化的 Paxos,而且简单易懂。因此我最终决定采用 Raft + RocksDB 的方案进行实现。
问题
Raft 是一个分布式一致性协议,而 RocksDB 是一个 K-V 数据库,在各自的领域应该都是闻名遐迩,在此不再多做介绍。在方案的实现过程中,碰到不少问题,其中的一个主要问题是:Raft 协议运行过程中需要维护一份日志,而 RocksDB 为了保障持久性,也会维护一份 WAL,这两份日志在数据内容上是高度重合的。这意味着在写入数据的过程中,需要再多写一份,这对于任何关注性能的系统来说都是不能接受的。
事实上很多分布式数据库系统都已经合并了这两条日志,比如某些魔改的分布式 MySQL 系统,以及 tikv(?我没调研)。他们采用的方案或是将存储引擎的 WAL 扩展支持一致性协议的特殊事件,或是在一致性协议的日志中嵌入一条存储引擎的 WAL,或者对某些特化的系统比如分布式日志系统,干脆直接将 Raft 的日志改造成存储引擎。在 Google 解决方案的过程中,我发现了 eBay 以前的一篇文章 [1],讲的就是如何把日志存储的日志和 Raft 的日志相结合起来,虽然只是一篇 workshop 的文章,但图文讲解还是让我茅塞顿开。
由于我采用了 RocksDB 作为存储引擎,显然我不希望去修改 RocksDB 的 WAL,这工程量太大了,不够回本的。因此我决定尝试定制 Raft 日志、关闭 RocksDB 的 WAL 的方案。在崩溃恢复的时候,使用 Raft 的日志去进行 RocksDB 的恢复。因为 RocksDB 是一个 LSMT 结构的系统,它在磁盘上持久化的 SST(Sorted String Table)都是只读的,即使崩溃也只是丢失内存中还没有刷盘的 memtable,这大大简化了崩溃恢复的工作量。
共享日志
共享日志需要为功能和性能考虑以下两点问题:
- 崩溃恢复时,怎么寻找最早未写入 RocksDB 的日志?
- 怎么减少小的磁盘 IO,尽量提高吞吐?
崩溃恢复
因为 RocksDB 只会丢失内存中的 memtable,而 KV 操作又都是幂等的,因此最简单的办法就是直接把日志从头重放到尾。显然这不是一个好方案,不说恢复时间很长,因为重复的 KV 操作导致的重复数据也带来了额外的磁盘压力,对 SSD 这种 GC 昂贵还有擦写次数限制的磁盘非常不友好。更好的做法是在 RocksDB 刷完 SST 的时候,记录下当前写下的 SST 的最大日志 LSN,同样写入磁盘。当重启恢复时查询到这个记下的 LSN,从这个点开始重放就好。
这个方案有两种实现办法:
- 用 RocksDB 提供的事件回调异步地完成 LSN 获取和写入
- 每次 put(k, v) 时额外 put 一个特殊的 key,举个例子 _raft_log_lsn,值是当前日志的 lsn
第一种办法异步写入总是有可能会写入失败(崩溃时),因此我更倾向于第二种实现办法,它唯一需要保证的是特殊的 key 不在用户合法的 key 的范围内。当 memtable 被写入磁盘成为 SST 时,这个特殊的 key 同样也会写入。那么当 RocksDB 再次启动时,只要查询一下该 key 的值就可以获取当前最大已经写入的 LSN。显然这种方法更加的优雅。当然这种方法并不能保证 LSN 和 SST 中的数据一定是一致的,除非在写入时能锁定 memtable 不让刷。
这里有一个注意点就是,RocksDB 默认的刷 memtable 策略是根据大小来的,因此可以先做 lsn key 的写入(不会改变 memtable 大小),再做 put(k, v),这样即使触发刷盘,也能保证数据和 lsn 是一致的。但是需要保证不会因为其他的什么策略刷盘导致刷了 lsn key 而数据丢了,目前看来还是比较困难的(不改 RocksDB 的话)。
合并提交
所有的数据库都有一个要求,那就是在用户请求返回前,数据一定以某种形式(e.g. WAL)已经在磁盘上了,从而保证持久性。但是当用户大量的请求都很小时,每个请求都单独落盘会导致大量的小 IO,而小 IO(小于 4KB)在任何类型的磁盘产品上都是慢且有害的。数据库系统中常用的一个优化手段是合并提交(group commit),将一组请求合并成一个请求同时提交到磁盘,然后再返回给用户。这样可以让每次的 IO 请求都尽可能的大,有效地提高了吞吐。
共享的 WAL 同样也可以采用合并提交的方式进行写入,但是注意的这时需要对上述崩溃恢复的方案做一些小的修改,即当所有 K-V 都 put 后再将 LSN 写入。
流程图
照猫画虎搞了个流程图:
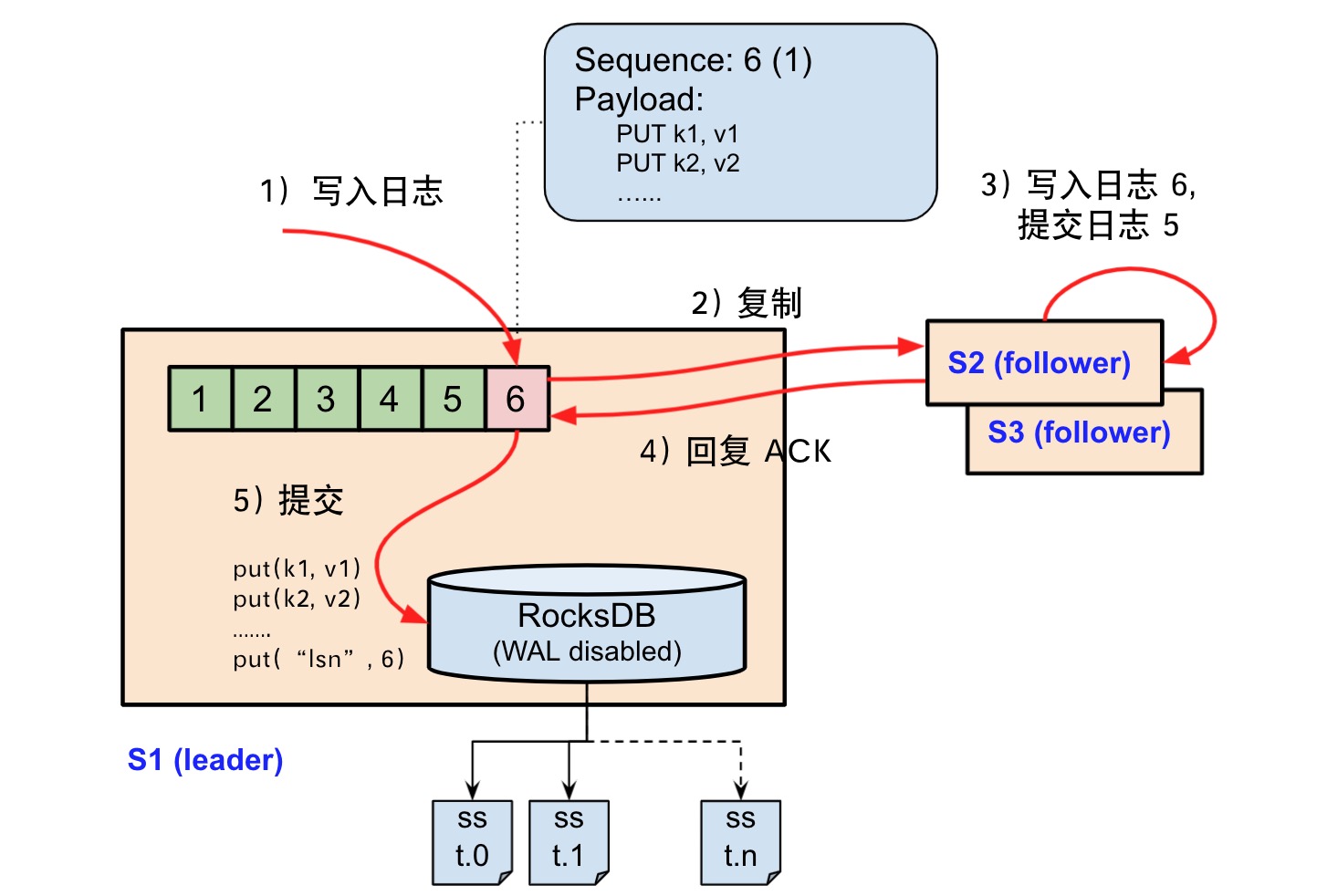
总结
总之只是一个小比赛引发的一点思考,实际上比赛是只有插入和查询,没有删除、覆盖写的场景,甚至消息只有 append。 RocksDB 并不是每个场景都能做到最优性能,但 Raft on 某种存储引擎的思路应该是通用的。
参考文献
[1] Designing an Efficient Replicated Log Store with Consensus Protocol. Jung-Sang Ahn, et al. 11th USENIX Workshop on Hot Topics in Cloud Computing 2019.